یادگیری ماشین به زبان کاملا ساده و عملی
یادگیری ماشین به زبان کاملا ساده و عملی
سلام دوستان
احساس کردم که تو سطح نت یه مثال ساده و خودمونی برای جا افتادن مسئله یادگیری ماشین خیلی کمه بخاطر همین دارم این پست رو مینویسم!
ببینین ماشین لرنینگ گزینه خوبیه برای شروع و وارد شدن به دنیای هوش مصنوعی
همونطور که از اسمش پیداس اینجا ماشین یاد میگیره!!!!
این یاد گرفتن هم دقیقا مثه سیستم مدرسه و دانشگاه خودمون،کل کارت اینه که بیای یه مدل رو به نحو احسن آموزش بدی و بعدا بتونی راهی جامعش کنی تا ازش استفاده کنن!
آموزش مدل چطوریه؟
فرض کنید در طول ترم یه استاد داری که هی مثال میزنه از درسی بهت و جوابشم همونجا بهت میده کلا هم در طول ترم 100 تا مثال با جواب درست داده بهت حال آخر ترم میاد میگه آقا جون من 100 تا سوال با جوابش بهت دادم حالا بیا این 10 تا سوال منو جواب بده اگه تونستی نمره قابل قبولی بگیری میگه خب شما آموزش دیدی و قبول شدی حالا میتونی تا آخر عمرت این مدل سوالا رو جواب بدی!!!! شمام میری جواب میدی! :)))
(خدایی فک کنم مخاطبم یه بچه 10 ساله هم باشه گرفته قضیه رو انقد صریح و خلاصه گفتم)
آموزش مدل هم همینطوره که شما با یه سری داده که تارگت های مشخص دارن میای یه مدل رو train میکنی بعد با یه سری داده که تارگتشو داری خودت مدل رو test میکنی بعد از اینکه مدلت دقت لازم برای پیش بینی رو داشت میگی حله پس من میتونم ازش برای داده هایی که تارگتشونو ندارم هم استفاده کنم.
کل اساس یادگیری ماشین تقریبا همین بود!
حالا بریم همینطوری خلاصه وار یه مثال عملی هم بزنیم که هیچ با تئوری حال نمیکنم! (لاتیشو پر میکند)
با پایتون کار خواهیم کرد اگه ندارین (ایییین بدههههههه) کلیک کنین اینجا دانلود و نصب کنین
و محیط ژوپیتر نوت بوک که اگه اونم ندارین میتونین از اینجاanaconda رو از اینجا کلیک کنین دانلود و نصب کنین که همراهش jupyter notebook هم نصب میشه! ) (اگه لینکا خراب شدن در مرور زمان حتما تغییر کردن و بهتره تو گوگل بزنین اسماشونو - اگر آموزش نصب میخوایین بازم گوگل نوکر شماست!
anyway... !!!
(بهتره یکم پایتون بلد باشین خداییش دیگه!!!!!! مسخره بازی که نیست ماشین لرنینگه!)
قدمای اصلی برای ایجاد و آموزش مدل:
- Import data - اضافه کردن دیتا
- Clean or Data normalization - (حالا تو ترجمه تقریبا صحیحش بگیم استاندارد سازی دیتا)
- Split the Data to train and test Sets - تقسیم دیتا به دو دسته آموزش و آزمون
- Create a Model - ایجاد مدل
- Train the model - آموزش مدل
- Make predictions - پیش بینی
- Evaluate and Improve - ارزیابی و بهبود
بریم تو کارش :
ژوپیتر رو اجرا کنید یه پنجره تو مروگر پیشفرضتون باز میشه گزینه new رو بزنید پایتون رو انتخاب کنید:
یه همچین صفحه ای رو بینید که به اون خط که مشاهده میفرمایین میگن سلول که محله نوشتنه دستوراته
(امیدوارم یکم پایتون بلد باشید اگر نه دیگه ادامه نده و برو پایتون یاد بگیر)
مرحله اول :
Import data - اضافه کردن دیتا
با این دستورات پایین اول کتابخونه هایی که مورد نیازه رو برای یه پروژه ساده یادگیری ماشیناضافه میکنیم:
اولین سلول ما میشه این :
import pandas as pd
from sklearn.tree import DecisionTreeClassifierخط اول کتابخانه پانداست ! پااااندا چیه ؟؟؟
پاندا یه کتابخونس برای مدیریت ویرایش و .. دیتا ها حالا خواهید دید با همین پاندا ما یه سری دیتا که قبلا ایجاد کردیم رو اضافه خواهیم کرد به پروژه چیز ترسناکی نیست از اسمش پیداس فقط دوس داره اول بیاد یه سلامی بده بخوابه :)))
خط دوم از کتابخونه sklearn اومدیم درخت تصمیم رو اضافه کردیم
کمرت شکست نه؟ توضیحش میدم حل میشه:))
ببین اول از همهدرخت تصمیم یه روش برای کلاس بندی از روی ویژگی هاست که قراره ازش استفاده کنیم مدلمون رو به این روش یاد بدیم بگیم مثلا اگه فلانی تو این ویژگی ها رو داری پس در فلان گروه جای میگیری! خیلی ساده خیلی روش های کلاس بندی وجود داره که این از نوع با نظارتش هست (حالا خواستم این مقاله ساده باشه بعدا حتما میرم سر توضیحات تخصصی این قسمت)
دقت کنید اون رو از sklearn که عشقه اضافه کردم ! sklearn یه کتابخونس که توی یادگیری ماشین خیلیییی به کارمون خواهد اومد و توش خیلی از روش های کلاس بندی و رگرسیون و.. وجود داره.
(بازم میگم خواستم این مقاله ساده باشه و خیلی ساده و خلاصه توضیح دادم وگرنه هر کدوم از اینا یه پست جداگانه خواهد داشت ایشالااااا)
حالا اینارو بنویسید تو سلول اول و shift+entre رو بزنید. که اجرا شن! اگه اروری نداد پایینش یعنی ok!
بریم سلول بعدی :
قبل از اینکه بریم سلول بعد این فایلی که اینجا برات میزارم رو دانلود کن:
نترس چیز عجیب غریبی نیست اگه با اکسل بازش کنی یه همچین چیزی میبینی :
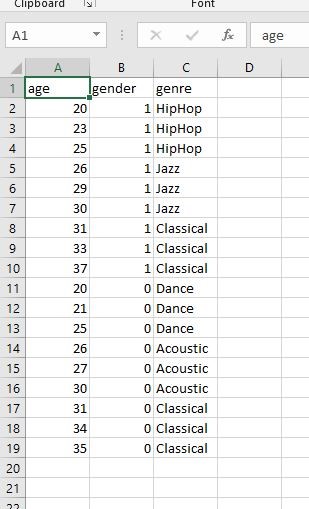
یه سری دیتاست که ستون اول سن ستون دوم جنسیت و ستون سوم سبک موزیکی که دوس دارن گوش کنن رو میده (فرض کن یه سری داده است که رفتن نظر سنجی کردن نوشتن)
حالا میخواییم با این مدل پیش بینی کنیم ببینیم احتمالا کی چی میتونه دوست داشته باشه !!!!
پس تو این سلول ما باید این دیتا هارو وارد پروژه کنیم بااین دستور:
music_data = pd.read_csv('music.csv')خیلی سادس دیگه به کمک پاندا اومدیم فایل رو وارد پروژه کردیم و در music_data ذخیره کردیم!
به چه شکلی؟؟؟ به شکل یک دیتا فریم ! دیتا فریم از اسمش دیگه مشخصه خداییش توضیح نمیخواد..
بريم سلول بعدي :
x = music_data.drop(columns=['genre'])
y = music_data['genre']
خط اول داده هاي ذخير شده رو با حذف ستون genre كه جواب سوال استاده!! در X ذخيره كرديم
خط دوم فقط genre رو در y به عنوان جواب سوال ذخيره كرديم !
بالاخره بايد سوال و جواب جدا باشه ديگه هرچند اگه قراره هردوتاشونم بديم به دانش آموز!
اگه X و y رو تو هر سلول جداگانه بنويسيم و اجرا كنيم (با shift+entre) اگه مشكلي تو كار نباشه بايد اينا رو ببينيم:
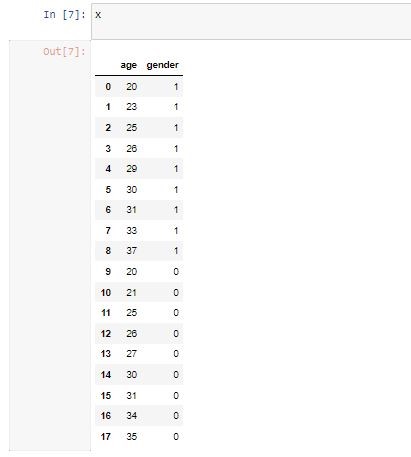
ویژگي ها يه جا تارگت ها يه جا!
بريم سلول بعدي :
()model = DecisionTreeClassifier
model.fit(x,y)
predictions = model.predict([[18,1],[25,0]])
خط اول يه مدل از نوع درخت تصميم ايجاد كرديم
خط دوم داده ها رو براي آموزش بهش داديم
اگه اجرا كنيم آموزش ميبينه
خط سوم دو تا داده جديد داديم گفتيم يه 18 ساله با جنسيت مرد و يه 25 ساله با جنسيت زن چه چيزي ميتونن دوست داشته باشن؟ برامون ژيش بيني كن.
سلول بعدی :
predictions
كه اگه همه چي رو دست انجام داده باشين يه چي مثه خط زير خروجي شماست :
خب پيش بيني كرد!!! ولي خب ببينيم چقدر موفق بوده!!!
سلول بعدی :
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_scoreگفتم sklearn خیلی به کمکمون میاد!!!
خط اول یه امکان رو اد میکنیم که باهاش داده ها رو به دو دسته تست و train تقسیم کنیم
خط دوم همونطور که ازش مشخصه میخواییم برای بدست اوردن میزان دقت مدلمون استفاده کنیم .(ارزیابی کنیم)
سلول بعدی:
x_train , x_test , y_train , y_test = train_test_split(x,y, test_size=0.2)
چهارتا متغیر ایجاد کردیم ترتیب مهمه ها و داده ها رو از X و y ریختیم توشون منتها!! 80% داده ها برای آموزش 20% برای تست!
انگار در طول ترم 80% سوالا با جوابا رو استاد داده حالا میخواد 20% سوالا رو پایانترم بدون جواب بده به دانش آموز و ببینه دانش آموز چه نمره ای میگیره!
حالااا سلول بعد :
model.fit(x_train,y_train)
predictions = model.predict(x_test)
predictions
چون میخواییم ارزیابی کنیم یه بار دیگه فیت میکنیم داده ها رو و تو خط بعدی با داده های تست پیش بینی میکنیم و چاپش مکنیم.
خلاصه و سادش کنم با 80% داده ها آموزشش میدیم میخواییم که با 20% داده هایی که تارگتشون مشخص نیست پیش بینی کنه و در predictions ذخیره میکینم این پیش بینی رو
خط بعد:
accuracy_score = accuracy_score(y_test ,predictions )
accuracy_score
پیش بینی ها و جواب های درست رو در accuracy_score قرار میدیم تا این مدل رو ارزیابی کنه:
که این خروجی بین 0 تا 1 قراره به ما بده هرچقدر مدل درست پیش بینی کرده باشه این میزان به 1 نزدیک تره و این مدل قابل اطمینان تره و دقت بالایی داره!
مطمئن باشید که ساده تر ازاین نمیشد یه مثال برای یادگیری ماشین زد!
تو پستای بعدی تخصصی تر و کاربردی تر میریم سراغ هوش مصنوعی و یادگیری ماشین
یاحق